It’s been 5 years now since I started working in academia. Not that long after all – but maybe just long enough to share some of the things that I’ve picked up along the way. Most of these aspects I’ve learned through the teachings of others.1 Hence, I don’t claim any ownership over these whatsoever. Should I’ve missed a reference, if you have feedback, or if you just think that I’m dead-wrong on something, please feel free to comment or to send me an e-mail. And finally, you know, the saying that one should take everything “cum grano salis” – it’s a thing.
Theory
- Try to write as logically and as convincingly as possible. Always check: Is this really the best argument that I can possibly come up with?
- Don’t write something with the spirit of “that’s probably the way others expect me to write it”. Instead, just focus on those arguments that you need for your current research question.
- Dare to present your own rationale – and don’t be afraid to label it as such. Only because another person’s rationale has been published already doesn’t mean it’s good. Likewise, only because your rationale hasn’t been published yet doesn’t mean it’s bad.
- Exploratory research and null-findings are important. When doing exploratory research – don’t be afraid to label it as such.2
- Argue from a two-sided perspective: There are always good counterarguments, the ‘truth’ is never easy, and maybe, just maybe, your initial hunch just wasn’t the final answer to begin with.
Research design
- Always use sufficient power. Rolf Zwaan: “To the best of your ability maximize the power of your research to reach the power necessary to test the smallest effect size you are interested in testing“. It’s a good idea to test your hypotheses with a power of at least 80% (Cohen, 1992). Or, even better, with a power of 95% – given that’s probably the same level as your confidence-interval for H0 (Moshagen & Erdfelder, 2015).
- Forget the “30 n per experimental group suffices”-rule of thumb.3 In most cases that’s just nonsense, given that it works only if you’re analyzing large effects (which, in the social sciences, is rarely the case).
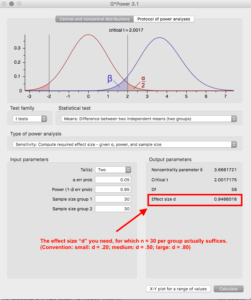
- Generally, be somewhat critical of rules of thumbs (that includes rules regarding sample size, model fit, reliability, also even effect size).4 Try to grasp the underlying issue as best as you can and then make an informed context-specific decision. I know that’s the road less traveled by — but hey, after all, we should at least be trying to do science.
- Aim to get samples that are ‘representative’. I know that’s both hard and ambitious; even more so, it’s a good idea to include that aspect into your grant proposals.
- Always do a small pretest to get qualitative feedback.
- Never do a small pretest to get quantitative feedback – because, actually, that’d just be another underpowered study. Either omit or do full-fledged study instead.5
- Try to collect actual behavioral data where possible.
- At the same time, collect self-reported data where necessary. The simple reason is: If you want to know what people think, well, you just have to ask.6
Item development
- Design items and corresponding variables according to the principle of compatibility (Fishbein & Ajzen, 2010).
- Use a 7-point answer format (Preston & Colman, 2000).
- Label each response category individually (Weng, 2004).
- When creating a new variable that you don’t have the time or resources to pretest: Always design at least 4 (or even better 5) items per variable, so that you can drop potentially malfunctioning ones and still retain a scale (a procedure that you should report, including all information in the online supplementary material).
Analyses
- Instead of traditional regressions or path analyses: Use SEM with latent variables. That way, you can partial out error/noise and have a better chance of explaining more variance in your outcomes – which is what you’ll probably want in most of the cases.
- Be parsimonious: Try to explain as much as possible within one single model. Einstein used only three variables for his most important finding, Hawkins is searching for only one theory of everything. So just because you’re having say two different outcomes you’re interested in, that doesn’t mean you also need two separate models.
- ANOVAS and regressions are basically the same (Cohen, 1968). Hence, why not include your experimental groups into a bigger theoretical model using contrasts?
- Report and interpret effect sizes.
- Report CFAs for all measured variables.
- Report omega instead of alpha.
- Learn R.
- Present extra analyses in the online supplementary material. (For example, via the open science framework.)
- Include your data to an online supplementary material.7
Language
- Use simple language.
- Stay calm: Try to convince through the quality of your ideas and not with the intensity of your words.
- Connect your sentences neatly.
- Make use of the different punctuation marks to create some flow. These include: . , ; – : ()
- To improve flow, put your subject at the beginning of a sentence.
- To create tension, put the main message, the gist, at the end of a sentence.
- Don’t alternate words just for the sake of it – sticking to the same words for the same ideas/actions/cognitions makes for an easier reading.
- There’s no space between words when separating them with a slash. Surprisingly, that’s not so well known/often ignored.
- If you’re not a native speaker of English: Before submitting your paper to a journal, try finding a professional or a friend who is willing to check on it. (Of course, that doesn’t apply to blogs 😉 )
- Revise your texts over and over and over again. It’s really not you being stupid, it’s good writing needing loads of time!
- It’s worthwhile reading the APA manual – it offers plenty of good advice.
- Never make absolute claims, always qualify!8
General aspects
- No matter how many publications, grants, or awards – please be humble. Yes, a large part of ‘success’ comes down to having worked hard and not being stupid, but a significant share also comes down to simply having been lucky.
- Listen to others and be open for new ideas. Especially in academia, there are just so many absurdly smart people out there who deserve your attention.
- Maybe you’ve just been wrong. I’ve already been wrong so many times. I’m currently wrong on so many things.9 Taking the approach that you’re wrong might sometimes be the only thing that you’re actually right about.
- Try not to be a dick – karma is a thing.
- Read blogs10 and follow people on Twitter11.
- Read everything from thebookoflife.org, waitbutwhy.com, and the100.ci.
- In general, read more books.
What are your thoughts? Have I missed out on something? Feel free to leave a comment!
To be continued …
Literature
- Cohen, J. (1968). Multiple regression as a general data-analytic system. Psychological Bulletin, 70, 426–443. doi:10.1037/h0026714
- Cohen, J. (1992). A power primer. Psychological Bulletin, 112, 155–159. doi:10.1037/0033-2909.112.1.155
- Elson, M., & Przybylski, A. K. (2017). The science of technology and human behavior. Journal of Media Psychology, 29, 1–7. doi:10.1027/1864-1105/a000212
- Fishbein, M., & Ajzen, I. (2010). Predicting and changing behavior: The reasoned action approach. New York, NY: Psychology Press.
- Lance, C. E., & Vandenberg, R. J. (Eds.). (2015). More statistical and methodological myths and urban legends. New York, NY: Routledge. Retrieved from http://lib.myilibrary.com?id=654507
- Moshagen, M., & Erdfelder, E. (2015). A new strategy for testing structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 23, 54–60. doi:10.1080/10705511.2014.950896
- Preston, C. C., & Colman, A. M. (2000). Optimal number of response categories in rating scales: Reliability, validity, discriminating power, and respondent preferences. Acta Psychologica, 104, 1–15. doi:10.1016/S0001-6918(99)00050-5
- Weng, L.-J. (2004). Impact of the number of response categories and anchor labels on coefficient alpha and test-retest reliability. Educational and Psychological Measurement, 64, 956–972. doi:10.1177/0013164404268674
Footnotes
- For example: Alain de Botton, Jacob Cohen, Malte Elson, Andrew Gelman, Philipp Masur, Miriam Metzger, Brian Nosek, Michael Scharkow, Sabine Trepte, or Tim Urban.
- For some interesting further thoughts on this, see Rolf Zwaan, Neurosceptic or Anne Scheel.
- That rule really seems to be a thing: In their meta-analysis of all the articles published in the Journal of Media Psychology, Elson & Przbylski (2017) found that “[a]cross all types of designs (see Table 2), the median cell size is 30.67” (p. 4). This has several (negative) implications for the achieved power: “Thus, the average power of experiments published in JMP to detect small differences between conditions (d = .20) is 12%, 49% for medium effects (d = .50), and 87% for large effects (d = .80)” (p. 4).
- If you want to know why, you could read, for example, Lance & Vandenberg (2015). Also: The irony when you look at the figure above …
- Or, as Malte Elson put it: “If you can’t afford power, don’t analyze your data with a statistical framework that requires it. Simple.“
- Although also that might change sometime soon …
- If your coauthors should be against that, try to convince them. If that shouldn’t work out, accept it stoically and then, at that vague and distant point in the future when you’re a PI yourself: Be the change you want to see.
- In the good old studivz.net (a German social network site before the days of Facebook), there was a group called: “Ich finde Verallgemeinerungen generell scheiße.” (engl.: “I think that generalizations are, in general, bullshit”). How true.
- Honestly, several of the points I’m raising here are rather ‘notes to myself’ than ‘things I’m already doing perfectly all the time.’
- For example: steamtraen.blogspot.de, the100.ci, andrewgelman.com.
- For example: @richarddmorey, @dingding_peng, @Research_Tim, @BrianNosek, @maltoesermalte, @Neuro_Skeptic, @JoeHilgard, @StatModeling, @sTeamTraen, @annemscheel.
You hardly need a native speaker, except that right there in point one you probably wanted “logically” and “convincingly”. The adjective/adverb distinction can be one of the hardest things for German/Dutch speakers to get right.
Thanks so much, Nick! That’s something I’m always struggling with, so thanks for letting me know — I’ve already corrected it.
My experience tells me that native speakers also benefit from co-writing/getting proofing feedback from non-native speakers, who don’t pick up the bad habits of many of us native speakers.
I agree. I’m often fascinated that in terms of languages there are sooo many different levels of skill — one can always improve, one can always learn something new, one can always find better expressions. And yes, that’s definitely true for both nonnative and native speakers. For example, I actually do prefer writing in English than in German; but that’s probably because English is just, well, nicer 😉